All about spaCy
In today’s digital age, the volume of textual data generated on the internet is nothing short of astronomical. As a result, understanding and extracting valuable insights from this vast sea of text has become a pivotal challenge for individuals and businesses alike. This is where Natural Language Processing (NLP) comes into play, and at the forefront of NLP tools and libraries stands spaCy.
spaCy is a powerful and efficient open-source library for natural language processing in Python. It has gained immense popularity in recent years for its speed, accuracy, and ease of use, making it an indispensable tool for a wide range of NLP tasks.
In this blog post, we will dive deep into spaCy, exploring its core features and capabilities. Whether you’re a seasoned NLP practitioner or someone just starting to dip their toes into the world of text analysis, this comprehensive guide to spaCy will equip you with the knowledge and skills to harness the full potential of this remarkable library.
Explore spaCy through python
Load the Model ( There are many language models available- I am loading English Model) 
Tokenization
Tokenization is the process of breaking down a text into smaller units, typically words or sentences. In natural language processing (NLP), these smaller units are referred to as “tokens.” 
Part of Speech Tagging
Part-of-speech tagging, often abbreviated as POS tagging, is a natural language processing (NLP) task that involves assigning grammatical categories or “parts of speech” to each word in a text 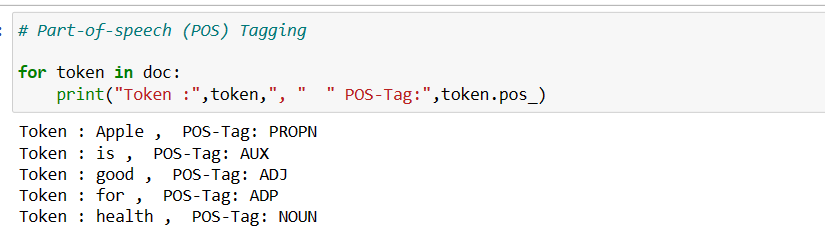
Dependency Parsing
(‘Apple’, ‘nsubj’, ‘is’): This means that “Apple” is the nominal subject (‘nsubj’) of the verb “is,” and “is” is the root of the sentence. (‘is’, ‘ROOT’, ‘is’): “is” is the root of the sentence, which is the main verb or the central word in the dependency tree. (‘good’, ‘acomp’, ‘is’): “good” is an adjectival complement (‘acomp’) of the verb “is,” indicating that “good” describes the property of “is.” (‘for’, ‘prep’, ‘good’): “for” is a preposition (‘prep’) that connects “good” to the word “health.” (‘health’, ‘pobj’, ‘for’): “health” is the object of the preposition (‘pobj’) “for,” indicating that “good” is for “health.”
Lemmatization
Lemmatization is the process of reducing words to their base or dictionary form, known as the “lemma.”
For example: Lemmatizing “running” would result in “run.” Lemmatizing “better” would result in “good.” 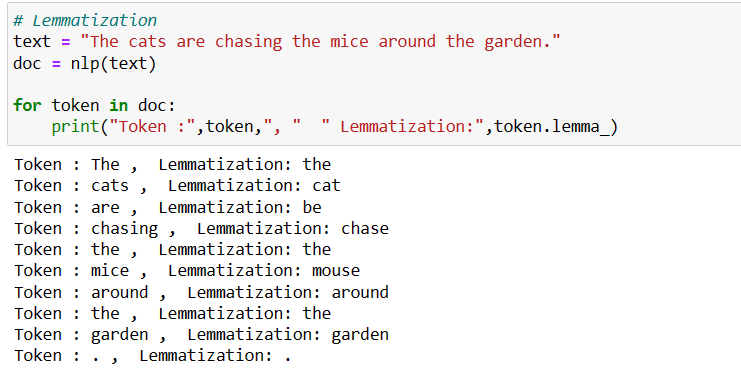
Named Entity Recognition
Named Entity Recognition (NER) is a natural language processing (NLP) task that involves identifying and classifying named entities in text. 
Find Similarity
In spaCy, similarity refers to the measurement of how similar or related two pieces of text are. It is often used to quantify the likeness or resemblance between documents, sentences, or words. SpaCy provides a similarity method that allows you to calculate the similarity between two spaCy objects, such as documents, tokens, or spans. 
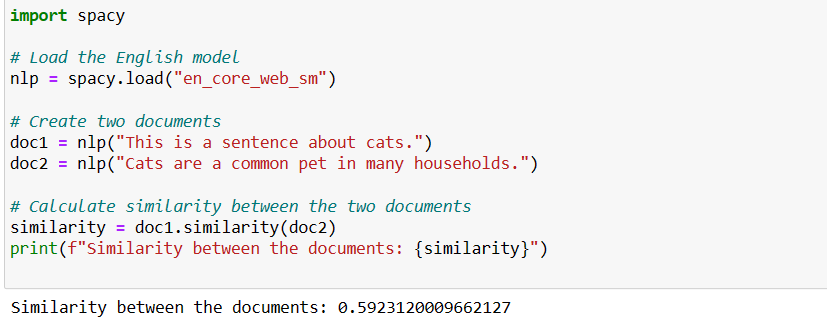
Entity Linking
It’s a natural language processing (NLP) task that goes beyond Named Entity Recognition (NER), which only identifies and classifies named entities. EL aims to link or connect recognized named entities to external knowledge sources, enabling additional information retrieval and disambiguation.
Since EL is the pipeline we add, make sure to install some modules before as mentioned below 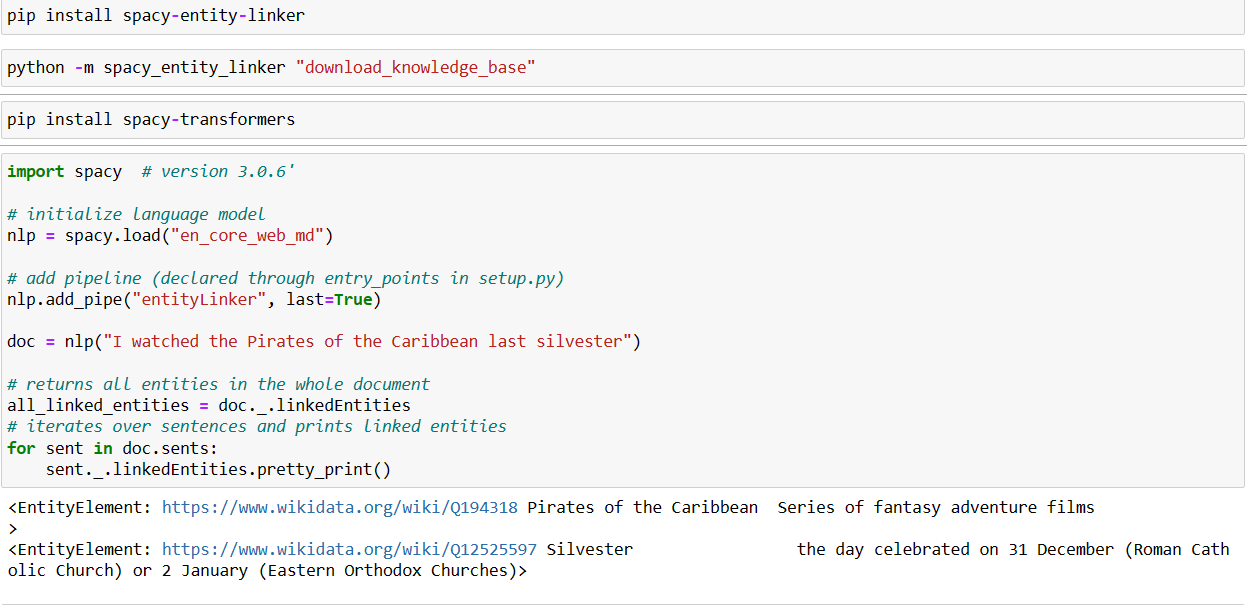
In the upcoming blog, we will delve deeper into topics such as text classification and the process of building a spaCy pipeline. As the discussion becomes more extensive, we’ll continue our exploration in the next blog post