Random Forest is combination of multiple decision trees. It can be used for Regression and Classification. Random Forest uses CART algorithm for every single decision tree. CART selects parent node and do split and goes on untill it finds the leaf node. C5.0 uses information gain to select parent node. But CART uses GINI index to select parent node. Below is the GINI Index formula.
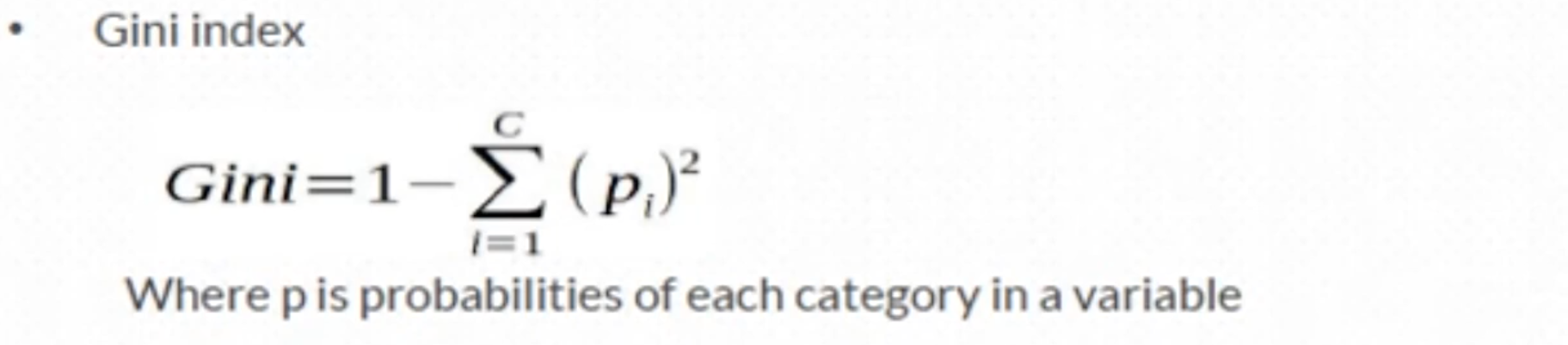
For Example if we have 10 variables, GINI index of all variables are calculated and the variable with low GINI index is selected as a parent node. In c5.0 , the variable with high Information Gain is selected as a parent node. GINI index measures impurity. So the variable with low GINI index should be selected as parent node. When GINI Index is zero, it says the variable is less impure and provide much information to the Target Variable.
Let us see how Random Forest is built. Example if we have 1000 observations, and 25 variables, then Random Forest selects m = sqrt(M) where M is number of variables. so here sqrt(25) is 5, so random forest selects randomly 5 variables to build every decision tree.
In our data, 66% will be training part, 33% will be testing part. Each tree is fully grown and not pruned. We have to predefine the number of Decision Tree, If we do not define the number of Decision Tree, then Random Forest will take the number of trees based on Error Rate. We can build trees untill the error no longer decreases. For prediction, a new sample is pushed down the tree. This process is iterated over all trees and the average is reported as prediction.
For Classification problem, when we pass the test data, 14 patterns say ‘yes’ and 6 says ‘No’, then we will go with ‘yes’ as per Majority. In case of Regression, we will take the mean if all the predicted values and we assign to test case.
Let us move with Random Forest python implementation which will help us to understand better.