Here we are going to work with Banking Data. Here the Target variable is “loan”. Please look at the data.
rm(list=ls())
setwd(“/Users/mac/Downloads”)
T1 = read.csv(“bank.csv”)
View(T1)
missingval = data.frame(apply(T1,2,function(x){sum(is.na(x))}))
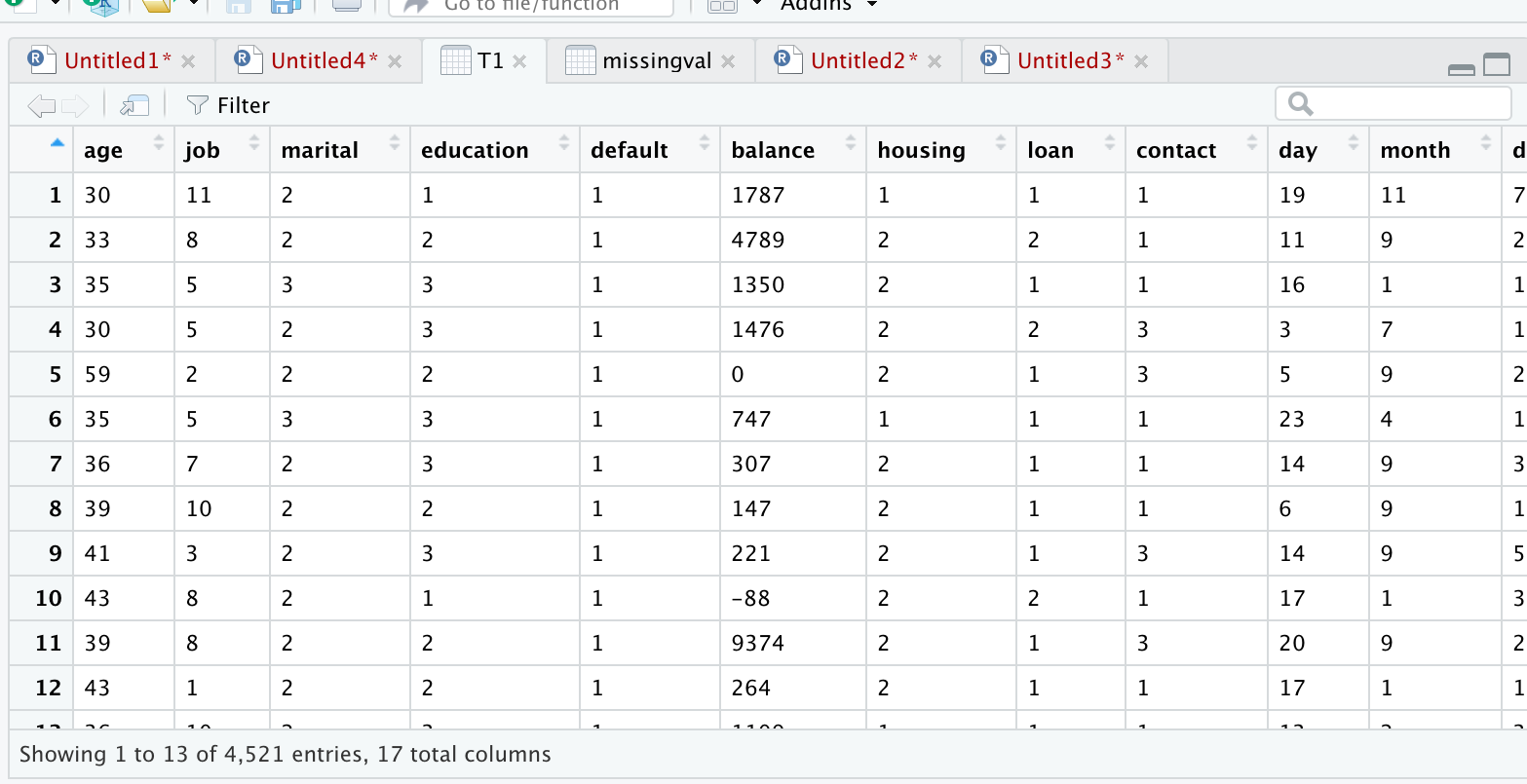
I just checked whether any missing values present in the dataset. Since it has no missing values, proceeding further. Also changed categorical variables to levels. Example for loan variable, we had values yes or no. Now its changed to 1 or 2. Screenshots of code and its output is given below.
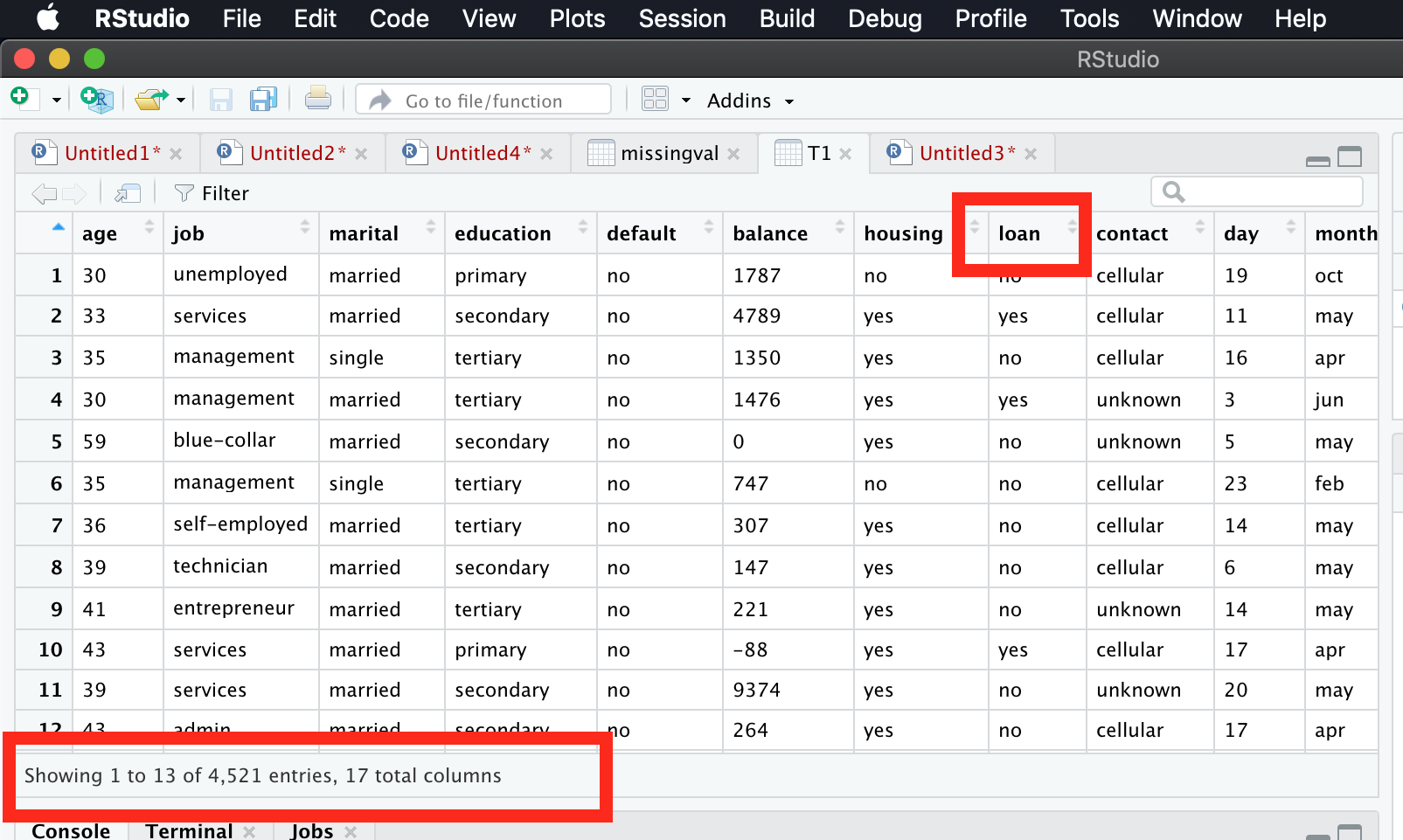
Now let us move to DT Classification. Before moving, we have to take the samples using stratified sampling. Since we have categorical variables we go for stratified sampling. If the dataset has only numerical variables, then we can go for simple random sampling. Here we go!!
library(DataCombine)
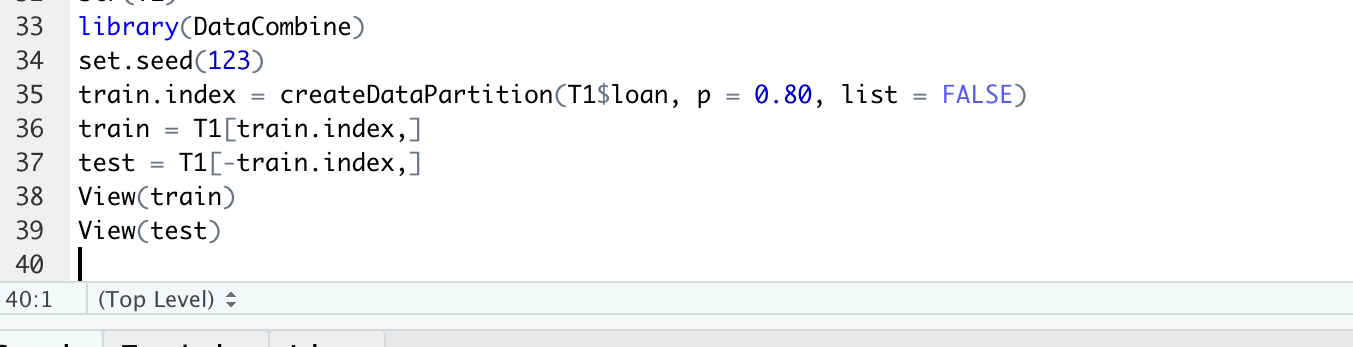
set.seed(1234)
train.index = createDataPartition(T1$loan, p = 0.8, list = FALSE)
train = T1[train.index,]
test = T1[-train.index,]
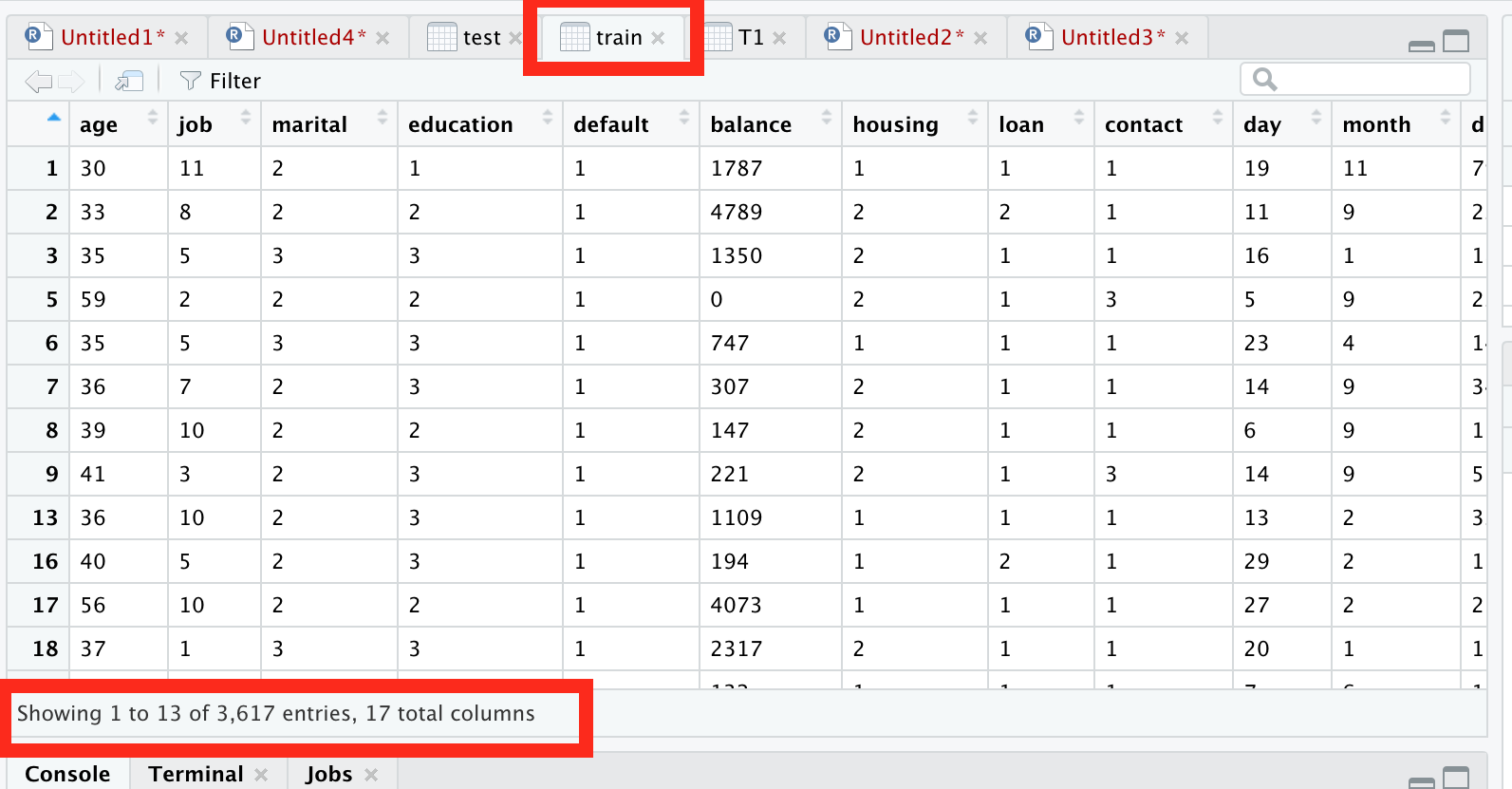
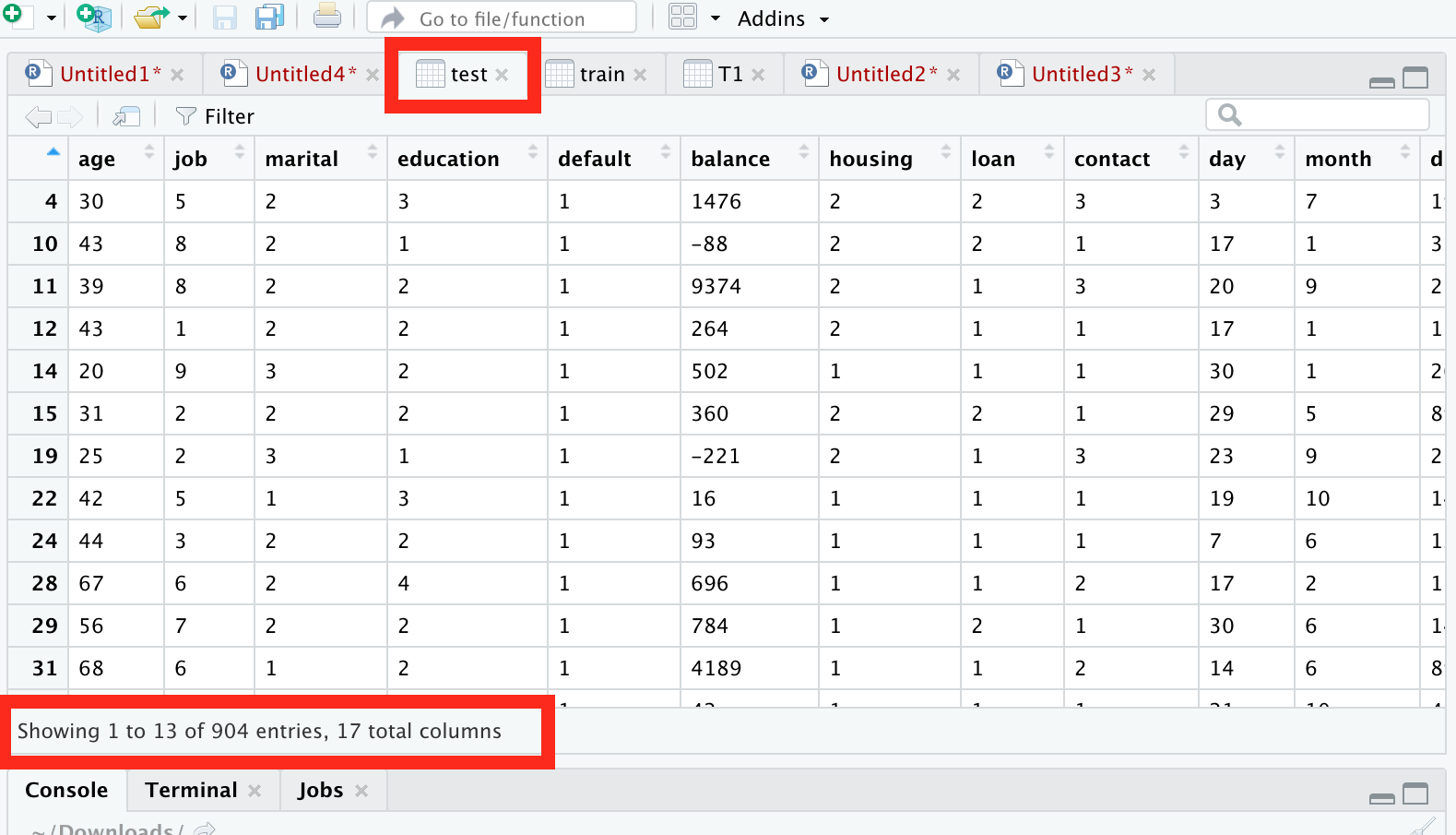
In Above commands, we divide the data in train and test.
Where train data contains 80% of data and test contains the remaining.
We are going to build ML model and test the model in the test data.
See below screenshots…
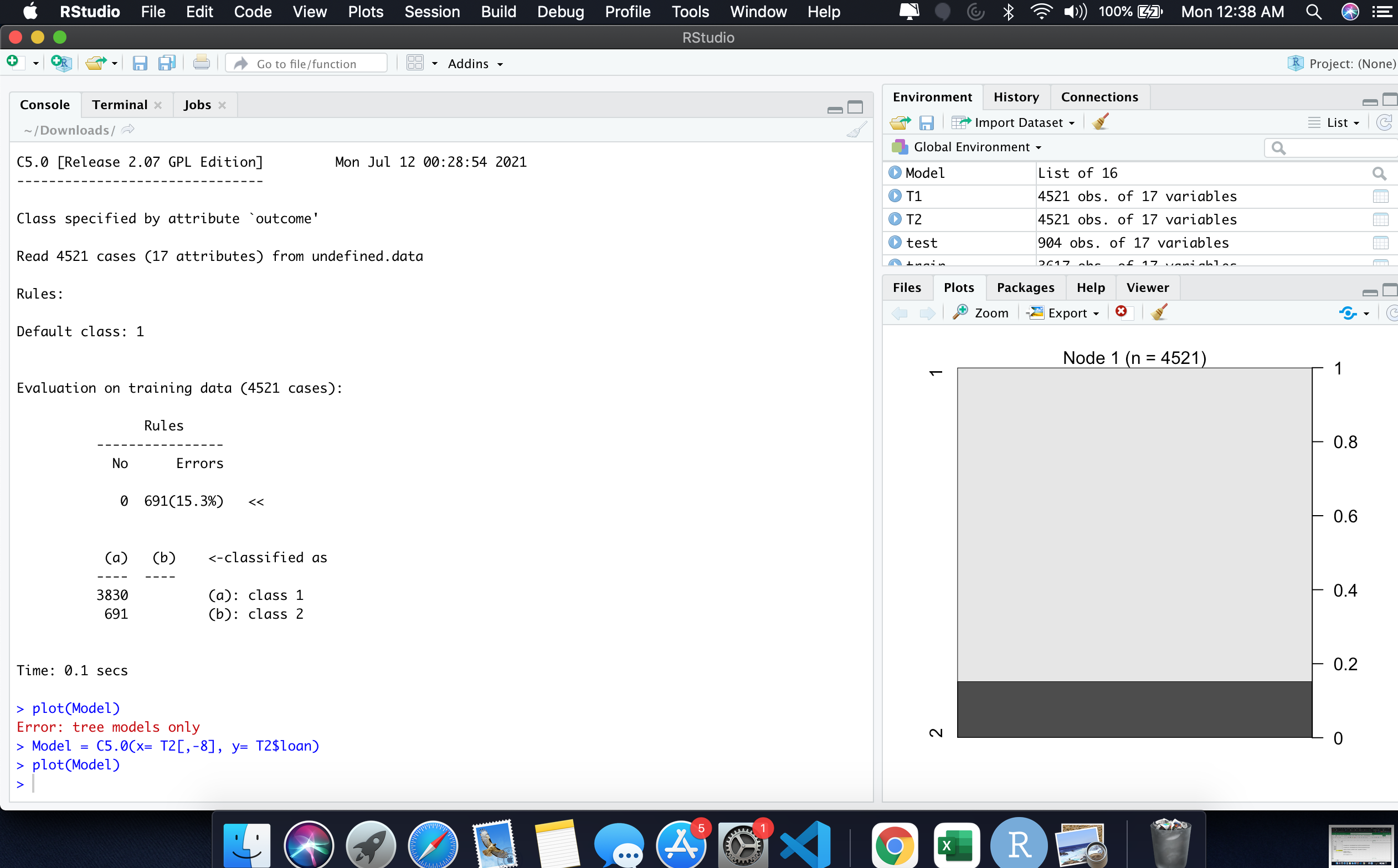
And here below , the Model is built and plotted. Output of Model and plot is given below the code. library(C50) T2 = as.data.frame(T1)
Model = C5.0(x= T2[,-8], y= T2$loan)
Model
summary(Model)
plot(Model)
 In below Image see the left for the Model and see the right for plot(Model)
In below Image see the left for the Model and see the right for plot(Model)
Now let us predict for test case And Evaluate
test_predictions = predict(Model, test[-8], type = “class”)
Evaluation_table = table(test$loan, test_predictions)
View(evaluation)
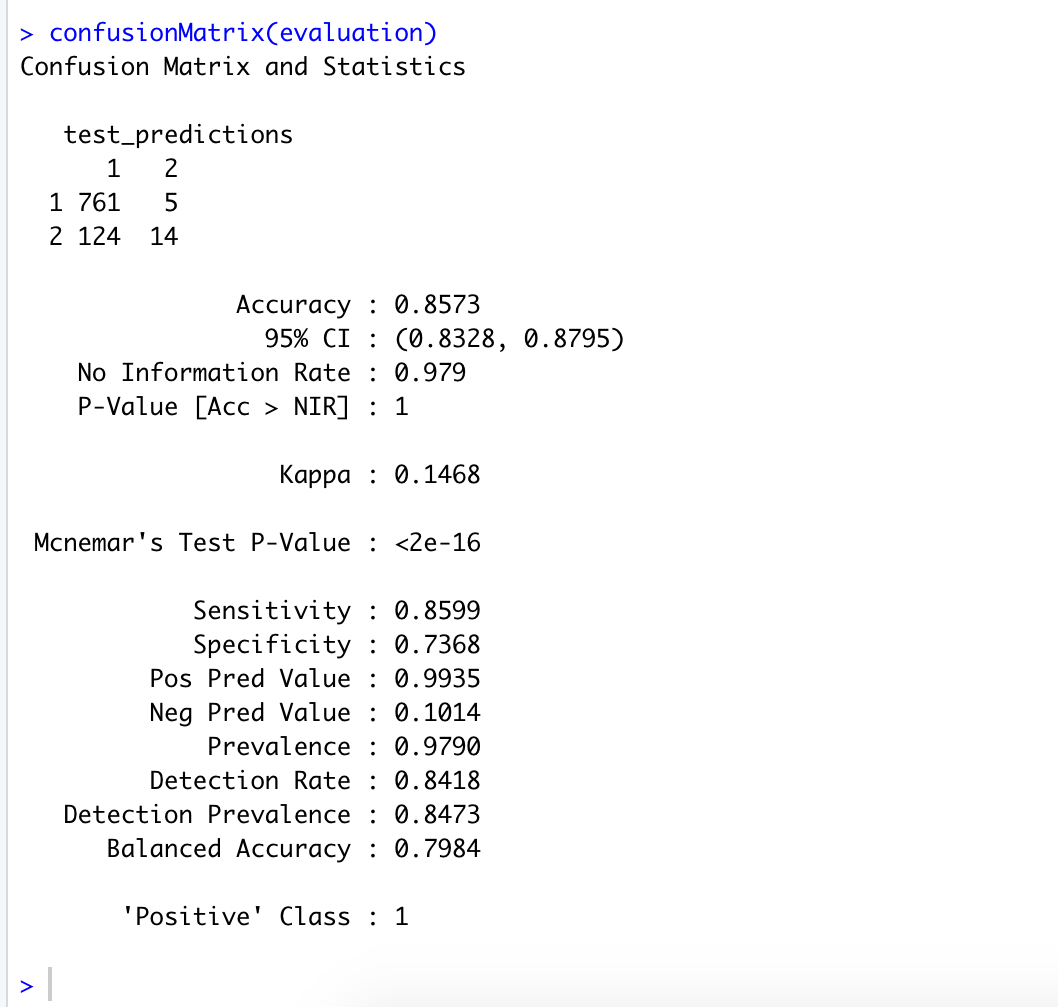
confusionMatrix(evaluation)
See below for corresponding screenshots

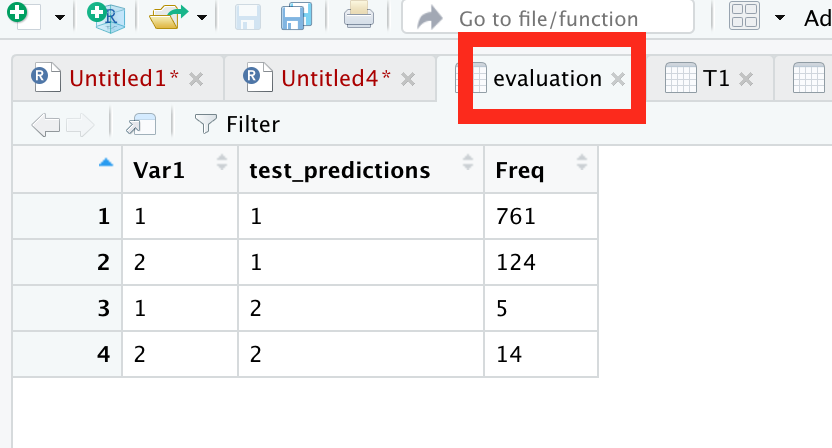
Here, loan variable had two values.”no”, or “yes”, We converted these into “no” = 1, and “yes” = 2,
Now in below table, first column is showing 1=”no” and
2=”yes”, and the second column is showing predictions. Here we interpret.
- 1 is correctly classified as 1, for 761 times..
- 2 is incorrectly classified as 1, for 124 times..
- 1 is incorrectly classified as 2 for 5 times..
- 2 is correctly classified as 2 for 14 times..
I hope this is clear, It will be most understood when you have ur hands in R!!.. Next would be DT Regression-R..