Here is the Decision Tree Classification -Python Implementation.
importing libraries and setting directory and reading the dataset
import os import pandas as pd import numpy as np from sklearn import tree from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
os.chdir(“/Users/mac/Downloads/”)
T1 = pd.read_excel(“Latest Covid-19 India Status.xlsx”)
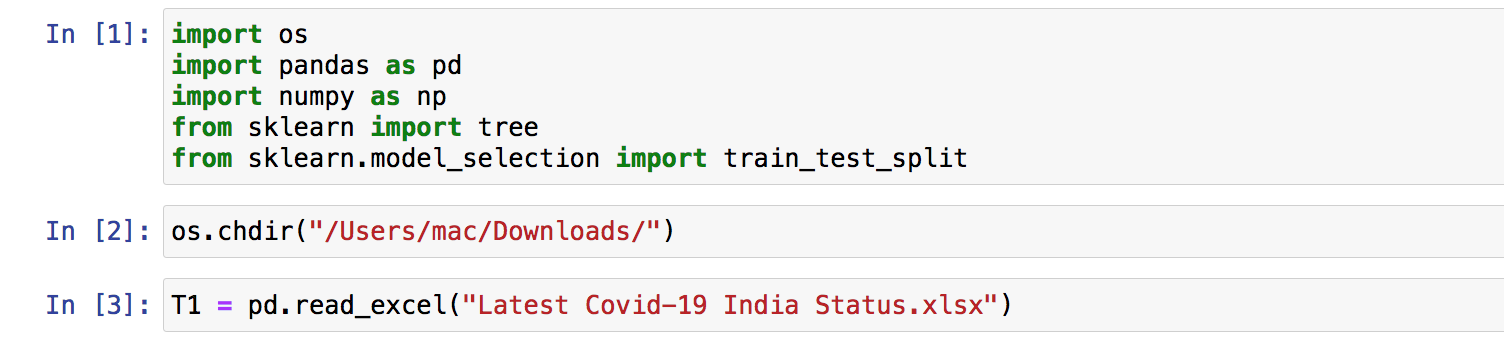
Glimpse of Data that we loaded
Using Stratified Sampling as we deal with categorical variables
Total Variables = 8
Target Variable = “ DR above 1%”
For X we have to give Independent Variables - 0 to 7 , (Starts with 0 and ends with 6- So 7 variables in total )
For Y we have to give Target Variable - 7- which takes 7(which is actually 8th variable since it starts from 0)
x = T1.values[:,0:7]
y = T1.values[:,7]
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2)
We mention test data to be 20% of total data. So we mention test_size=0.2

Building Classification Model
Here we build C5.0 algorithm, so we put criterien=’entropy’, if we want to use CART , then we mention ‘GINI’ Inside fit, we give the data using which the Model is trained.
Clfr = tree.DecisionTreeClassifier(criterion=’entropy’).fit(x_train,y_train)
Then we go for Predictions for the Test Dataset. We feed x_test into the Model and see the results. We compare the results with the existing results (y_test), and calculate accuracy like below..
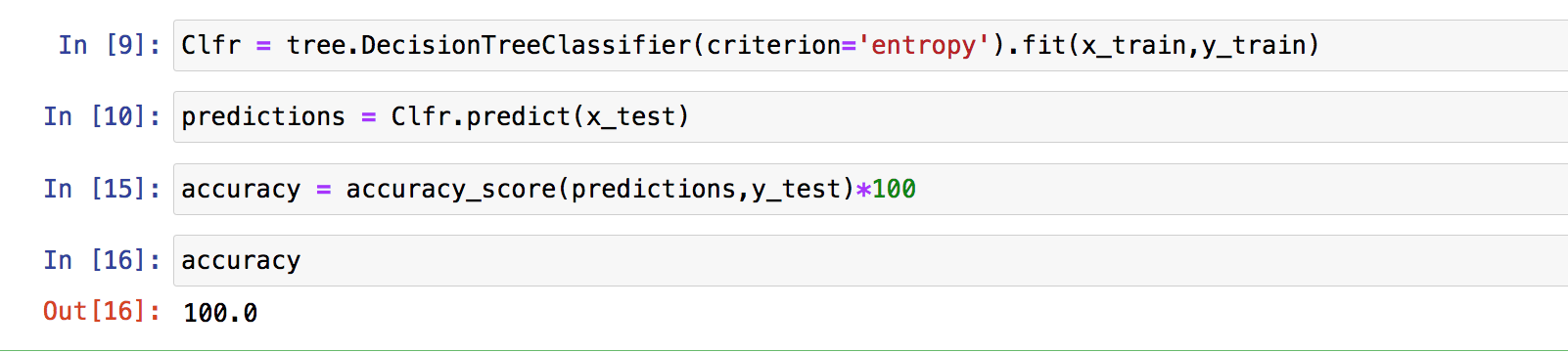
With this we will end up and will see the Decision Tree- Regression in Python in next post.